 Xue Hong pouring plates
Xue Hong pouring plates  Shown are the bacteria in the first
batch. This corresponds to the first 30 strains in T-4.2-A (numbers
1-27). Blotting begin in the upper left; 6 strains per line; 5
lines per plate
Shown are the bacteria in the first
batch. This corresponds to the first 30 strains in T-4.2-A (numbers
1-27). Blotting begin in the upper left; 6 strains per line; 5
lines per plate4. Determination of wild rhizobia by numerical taxonomy
Abstract: The diversity of root-nodule isolates was investigated by
numerical taxonomy of phenetic characters. Huge differences in
growth vigor necessitated the development of a chi-square-based
similarity coefficient. The resulting classification generated a
clear-cut division between rhizobia and freezer contaminants. Wild
Xiaman and Huanglongsi rhizobia were divided into vetch-nodulating
rhizobia and an Astragalus-Onobrychis group, but Sinorhizobium
appears to be rare at Xiaman.
4.1. Materials and methods
4.1.1. Isolation and maintenance of wild bacterial strains: Sichuan strains were isolated from nodules collected in the field either from temperate grassland sites at Xiaman (Ruoergai county,section 1.2. for description) or Huanglongsi (Songpan;100km west of Xiaman,similar climate) or from the subtropical southern Chengdu suburban-subagricultural area. Exact information on the origins of the strains is stored in DATASET.RHI, note for SUUGLRZ200-250 plant specimen were taken, partly stored at Prof. Tan Zhongming, Dept. Botany, SUU, partly stored at the central herbarium of SUU. Note that for SUUGLRZY??,SUUGLRZZ?? and SUUGLRZU?? the transect data (DATASET.TRA) are also relevant. Whereas Xiaman nodules collected in the field had been temporarily stored on test tubes with KCl (in 1993 and 1994) or Eppendorf tubes containing paraffin (in 1995), direct isolation in the field was the method of choice in 1996. Desiccated nodules were allowed to rehydrate in water overnight, then the nodules were dipped into alcohol and surface-sterilized by 0.1% HgCl2 for 1-4min (1993-94) or 10% H2O2 for 1-3min (1995-96), following #Jordan (1984). After sterilization and one wash in distilled water, we stroke the squashed nodules on petri dishes with #Vincent's (1970) YMA yeast-mannitol medium containing 25ppm of Congo red. Colonies were purified by streaking out and isolation of apparently single colonies and maintained on slope agar with Vincent's medium (MEDIUM.VIN) at 4oC and transferred to fresh slopes about two times a year. A backup copy of the slopes was covered with paraffin. Please note that few inoculation experiments - usually considered the acid-test for rhizobianess (#Jordan 1984) - were successfully performed. Of the field isolates, only (13) and (14) had been shown to form nodules on their respective host (M. sativa, V. sativa) in vitro (test tubes slopes following #Vincent 1970)7, so this study is unorthodox in that it also shall prove whether dubious isolates are indeed rhizobia.
4.1.2. Origin of control strains: Except the Xiaman and Chengdu strains, we furthermore include 9 type strains obtained from Prof. Chen Wenxin (Beijing Agricult. Univ.), and two strains from Hongya peanut rhizobia (#Zhang 1996). As controls, several non-rhizobial strains were included: 2 bacilli (as Bacillus is the most abundant bacterium in Ruoergai soils, see Long Zhangfu 1994), Nitrobacter (maybe contaminated, it grows quite well on any medium) and Agrobacterium from the alpha-Proteobacteria (rhizobia are part of), Pseudomonas pseudoalcaligenes for the beta-Proteobacteria, E.coli and Vibrio sp. for the gamma-Proteobacteria, some cocci and Staphylococcus aureus (some obtained form Ge Shaorong, Sichuan Univ., others from the West China Univ. Medical Sciences).
Note: Huanglongsi and Xiaman are locations on the grassland. "*"field plot inoculated with Huanglongsi/Xiaman rhizobia mixture; "--" indicates that a strain is included in T-4.2-A but not in the analysis (not satisfying the criteria of (4.1.8.)).
Table T-4.1-A: Strains included in the analysis
-------------------------------------------------------------------
Temp. Number Strain Host plant or species Origin
-------------------------------------------------------------------
01 y043 SUUGLRZ221 Medicago lupulina L. Huanglongsi
02 Y057 SUUGLRZ223 Oxytropis kansuensis Bge. Xiaman
03 y071 SUUGLRZO-11 Onobrychis viciaefolius Xiaman *
04 y084 SUUGLRZO-02 Onobrychis viciaefolius Xiaman
05 Y089 SUUGLRZY03-0 O.kansuensis Xiaman
06 Y099 SUUGLRZX6-8 Vicia sativa L. Chengdu
07 y102 SUUGLRZO-14 Onobrychis viciaefolius Xiaman
08 Y105 N15 JM107 Escherichia coli
09 y113 SUUGLRZO-05 Onobrychis viciaefolius Xiaman
10 Y149 N16 Staphylococcus aureus
11 Y171 SUUGLRZ248 Astragalus mahoschanicus Xiaman
12 Y180 SUUGLRZO-03 Onobrychis viciaefolius Xiaman
13 Y182 SUUGLRZ208 Melilotus suaveolens Ledeb. Huanglongsi
14 P184 SUUGLRZ215 Vicia sativa L. Huanglongsi
15 Y206 SUUGLRZ94361 Trigonella archiducis-nicolai Huanglongsi
16 Y214 SUUGLRZ211 Vicia sativa L. Huanglongsi
-- Y230 SUUGLRZ234 Onobrychis viciaefolia Scop. Xiaman
17 Y251 SUUGLRZX1-3 Glycine max Chengdu
18 y252 SUUGLRZY21-7 A.sungpanensis Xiaman
19 y281 SUUGLRZX6-9 Glycine max Chengdu
20 Y301 SUUGLRZ94364 Astragalus mahoschanicus Tangke
21 Y325 HAMBI 540 [=T2] Rhizobium galegae Finland
22 Y335 SUUGLRZX3-1 Glycine max/arrow-leafed cv Chengdu
23 Y338 N22 Nitrobacter sp
24 Y364 N03 Cocci (undetermined)
25 P413 SPR2-9 Arachis hypogaea Hongya
26 Y429 SUUGLRZZ07-5 L.pratensis Xiaman
27 Y450 USDA205 [=T6] Sinorhizobium fredii Central N China
--
--
28 Y459 SUUGLRZ236 Vicia sativa L. Xiaman
29 Y498 NZP2213 [=T9] Rhizobium loti New Zealand
-- P518 SUUGLRZO-17 Onobrychis viciaefolius Xiaman
30 y535 SUUGLRZ229 Astragalus prattii Xiaman
31 Y541 CIAT899 [=T4] Rhizobium tropici Mexico
32 Y543 SUUGLRZ200 Trigonella archiducis-nicolai Huanglongsi
33 Y578 N02 B-13 Bacillus thuringiensis
34 P580 SUUGLRZ201 Medicago lupulina L. Huanglongsi
35 Y612 N01 AS 1.398 Bacillus subtilis
36 Y642 SUUGLRZ94380 Hedysarum tanguticum Fedtsch. Heishui
37 y645 SUUGLRZX6-2 Vicia faba Chengdu
38 y680 SUUGLRZ224 Vicia faba L. Xiaman
39 Y691 SUUGLRZX6-5 Trifolium repens Chengdu
40 Y712 USDA2370 [=T3] Rhizobium leguminosarum USA
41 Y731 N19 Vibrio sp
42 Y738 USDA1002 [=T5] Rhizobium meliloti USA
43 Y771 SUUGLRZX6-7B Vicia sativa L. Chengdu
44 Y799 CCBAU2609 [=T7] Rhizobium huakuii Nanjing
45 P816 SUUGLRZZ18-03(25)A.polycladus Xiaman
46 Y850 CCBAU3306 [=T1] Rhizobium tianshanense Xinjiang
47 Y861 N04 Pseudomonas pseudoalcaligenes
48 Y886 SUUGLRZX6-6 Trifolium repens Chengdu
49 Y903 SUUGLRZ94378 Hedysarum tanguticum Fedtsch. Heishui
50 y919 SPR2-8 Arachis hypogaea Hongya
51 Y945 USDA6 [=T8] Bradyrhizobium japonicum USA
52 Y957 SUUGLRZO-18 Onobrychis viciaefolius Xiaman
53 y961 SUUGLRZO-12 Onobrychis viciaefolius Xiaman
54 Y966 SUUGLRZZ14-1 A.polycladus Xiaman
-- X6-7A (/Agrobacterium tumefaciens LBA 4404 (WHY)
-- 219 (/X6-7A) Vicia sativa Chengdu
----------------------------------------------------------------------
----------------------------------------------------------------------
4.1.3. Choice of biological tests: Published articles either on rhizobial taxonomy or on selective media for rhizobia into a database (see appendix: DATASET.SEL, it contains some 700 entries on about 250 different characters from a score of articles) and then selected for those non-laborious tests either promising for selectivity for rhizobia or yielding much information (concentrations of selective agents near the LD50 dose).
4.1.4. C/N utilization and resistance tests: Tests were done in two batches: in the first batch 2000ppm of any C/N source was added to the previously C/N-free agar (modified #Pagan's (1975) medium=MEDIUM.PGM); in the second batch resistance-generating agents were added in the concentrations specified individually (all blank numbers meaning ppm) to Vincent's YMA (=MEDIUM.VIN). Then the mixture (usually in a 100ml Erlenmeyer flask; for a detailed listing see DATASET.TAX or T-4.2-A) was autoclaved for 15min at 121oC (with our autoclaves the time the temperature is above 100oC is about 45 minutes), as control and for use in section 5 each time two plates inoculated with Chengdu and grassland soil bacteria were included.
4.1.5. Notes on other biochemical tests
(second batch):
T01: 3-glycoside sugars experiment (#Bernaerts 1963) : first grow the
bacteria 1-2 days on LO(=lactose 10000, yeast extract 1000)
(actually we incubated 9 days), then cover the Petri dish with a
shallow layer of Benedict's reagent (Na2CO3 100000, CuSO4 17300,
Na-citrate 17300. Producing 3-glycoside sugars colonies will be
surrounded by an orange CuO2 ring after one hour of incubation.
T02: production of organic acids: cultivate 20 days on bromothymol
blue YMA 20 (#Norris
1965)6,check whether after 9 days the agar has changed color
(from blue to yellow) or not
T03-06: growth on different temperatures on YMA
T07: Melanin production (#Cubo
1988)5, incubate on TY (=tryptone 5000 yeast extract 3000
CaCl2.6H2O 1300,#Beringer
1974)) containing L-tyrosine 600 and CuSO4 40. Drop 0.05ml 10%
SDS in TBE (pH=8.3;Tris 10800;boric acid 5500;4 ml 0.5M EDTA) on
the colonies. After 1-24 hrs of incubation, melanin production will
occur.
T08: Growth in "Mg-free" DM with MnSO4 2000
T09: Growth at pH=5.0 with MnSO4 2000
T10: Onobrychis inoculation. Prepare 50ml of plant cultivation
medium (=MEDIUM.CHN, modified after Chen) into plastic-sealed 100ml
Erlenmeyer flasks and sterilize them. After that plant seeds which
had been incubated for three days. Seed preparation: Seeds were
obtained from the Ganzi district agriculture office; after removing
the seed-coat, seeds were
sterilized in 75% ethanol for 4 minutes and 3% H2O2 for 10 minutes,
then washed once, soaked at 4oC overnight and then transferred to
Petri germination dishes containing 1% agar. Resulting germination
rate was 125/3 84=32.5%, and plants uninfected by fungi were
transferred to the above-mentioned Erlenmeyer flasks. There were
inclubated at 20oC (day, 16hrs) at 4oC (night,8hrs) which should
simulate putative Ruoergai field conditions for May-June(14hrs
daylight, 1041 J/cm2*day photosynthetically effective irradiation,
soil temperature at 5 cm depth average 8.2oC, minimum 5.6oC,
maximum 16.6oC;see #Yang 1993A,
who published Hongyuan 1960-80 climate data). As light source,
fluorescent light was chosen, because it has been established that
the legume phytochrome system is quite sensible to far-red
irradiation (#Lie 1971,#Gibson 1980,#Liu Changpei 1987).
4.1.6. Blotting colonies onto the agar plates: After pouring the plates they were stored in inverted position overnight (which ensures a dry surface). With an inoculation loop, colonies were taken from agar storing slants, diluted in a 2ml flask with sterilized water, and blotted onto agar plates (30 colonies each). The fixed position of each strain on the agar plates for all resistance and C/N utilization tests was randomized.
Xue Hong pouring plates Shown are the bacteria in the first
batch. This corresponds to the first 30 strains in T-4.2-A (numbers
1-27). Blotting begin in the upper left; 6 strains per line; 5
lines per plate
4.1.7. Colony growth scoring: The plates were subsequently incubated at 28oC (except the temperature tests which were grown for the same period at the respective temperatures), after which the colonies were assessed. According to #Jordan (1984) , fast-growing root nodule bacteria (genus Rhizobium) form visible colonies (2-4mm diam.) on YMA within 3-5 days and Bradyrhizobium (slow-growers) need 5-7 days to form 1mm diam. under the same conditions. To assure reproducible results, we waited till 9 days for all strains, and then entered "n" for no growth, "b" for bad growth (visible, but not white), "y" for normal growth (opaque), "s" for slimy growth (colony size more than ca. 5mm) and "?" for unclear or ND into DATASET.TAX. As far as tests for different growth temperature optima are concerned, the nth day growth occurred is directly entered as number.
------------------------------------------------------------------------------------------------
Table T-4.1-B: Different ways for calculating similarity of two strains (excerpt from PROG_CLU.C)
-------------------------------------------------------------------------------------------------
float GetEuclidDistFromContigencyTable
(float sima,float disb,float disc,float simd,char methchoice)
{
/*sima and simd refer to similarities in a 2*2 contingency table, and correspond exactly to a and d in #Sneath 1973,#Zhong 1990 or the Chi-square test; disb and disc correspond to the dissimilarities b and c; methchoice is the method of calculating an Euclidean distance matrix chosen*/
float tmpsim; /*similarity (of two strains or other things)*/
if (sima+simd+disb+disc==0) return 1; /*no data*/
if (methchoice==1) /*Simple matching coefficient, reviewed by #Sneath 1973*/
tmpsim=((sima+simd)/(sima+simd+disb+disc));
if (methchoice==2) /*Positive matching, #Sneath 1957*/
{if (sima+disb+disc>0) tmpsim=(sima)/(sima+disb+disc);else return 1;}
if (methchoice==3) /*Matching without vigor, #Sneath 1968*/
tmpsim=1-(2*sqrt(disb*disc))/(sima+simd+disb+disc);
if (methchoice==4) /*Matching without vigor, #Sneath 1968,a more general version
for discovering strong NEGATIVE relations (useless in the
in the original bacteriological context, but might prove useful
for non-bacteriological applications)*/
{
if (disb*disc<disb*simd)
{
tmpsim=1-(2*sqrt(disb*disc))/(sima+simd+disb+disc);
rel_modal=0;
}
else
{
tmpsim=1-(2*sqrt(disb*simd))/(sima+simd+disb+disc);
rel_modal=1;
}
}
if ((methchoice==6) || (methchoice==7))
/*premanipulating data for modified Chi-square*/
{
float minsim,mindis; /*minimal values for similarity & dissimilarity
in 2*2 contingency table*/
if (sima<simd) minsim=fabs(sima); else minsim=fabs(simd);
if (disb<disc) mindis=fabs(disb); else mindis=fabs(disc);
if (methchoice==6) /*modified Chisquare*/
{sima=simd=minsim;disb=disc=mindis;}
if (methchoice==7) /*semimodified Chisquare*/
{
sima=minsim/2+sima/2;
simd=minsim/2+simd/2;
disb=mindis/2+disb/2;
disc=mindis/2+disc/2;
}
}
if ((methchoice==5)/*original Chisquare,algorithm following #Wall 1986*/
|| (methchoice==6) /*modified Chisquare*/
|| (methchoice==7) /*semimodified Chisquare*/)
{
tmpsim=sima*simd-disb*disc; /*do a chisquare if possible*/
if (tmpsim<(0.5*(sima+simd+disb+disc)/*Yates correction*/
+0.0001/*safety valve for inaccurate number crunching*/)
|| (!(sima+disb)||!(simd+disb)||!(sima+disc)||!(simd+disc)))
/*data insatisfactory*/
return 1;
else {
tmpsim-=0.5*(sima+disb+disc+simd);
tmpsim*=tmpsim;
tmpsim*=(sima+disb+disc+simd);
tmpsim/=((sima+disb)*(simd+disb)*(sima+disc)*(simd+disc));
tmpsim/=(1+tmpsim);
}
}
if (tmpsim>1) printf("Calculation error of similarity in clusterit.");
return (sqrt(1-tmpsim)); /*Euclidean distance, #Sneath 1973*/
}
--------------------------------------------------------------------------------------------------4.1.8. Cluster analysis of strains: All information on growth quality was discarded, ("b","s","y" and numbers all scored as positive, "n" as negative) and an ANSI C program for UPGMA cluster analysis (#Chen 1986,#Sneath 1973) was generated. Strains giving 20-80% overall positives and 10-90% positives in each of both batches were included in the analysis. Variable methods of assessing the similarity between pairs of strains were employed (see T-4.1-B and PROG_CLU.C). As a control, a Farris-Wagner cladistic analysis was performed (#Zhong 1990:173; program lost and thus not in the appendix). Trees were generated from PHYLIP format treefiles with the DRAWTREE program of Joseph Felsenstein's PHYLIP (Version 3.57c for DOS, July 1995, the program is internet public domain at http://evolution.genetics.washington.edu/).
4.1.9. Cluster analysis of characters: Using the same data matrix, we did the same analysis on the biochemical tests. Tests giving overall 10-90% positives were included in the analysis.
------------------------------------------------------------------------------------------------------- Table T-4.2-A: Results of biochemical tests with 60 strains (also given as DATASET.TAX) CHE GRA -------------------------------------------------------------------------------------------------------- A01 bacitracin 50_ysyyys_ynynyy_ynbysb_syyyyy_yyyy??_sy?yyy_yyynyy_ybnyyy_yyyyyy_yyyyyy 131 976 A02 chloramphenicol 20_yyyyny_nnnyyn_ynnysn_bbnnby_ybnn??_yn?yyn_nynyyy_ynnnyn_ynynny_yynynn 64 72 A03 erythromycin 50_ynynnn_nnnyyn_y??yyn_bnnnny_nnnb??_nn?nnn_nbnyny_nnnyny_nbnnyb_nsnnnn 15 16 A04 gentamicin 10_nnnnnn_nnnnnn_nnnnnn_nnnnny_nnnn??_nn?nnn_nnnnnn_nnnnnn_nnnnnn_nnnnnn 2 0 A05 penicillin 5_ssyyys_ynybyn_yynysn_syyyby_?nyy??_sb?ysn_nybyyy_syny?y_y?ynyy_yyyyyy 177 340 A06 streptomycin 10_yssyyy_ynyyyn_yynysn_sbyyyy_byyb??_sb?yyy_yyyyyy_ynnyyy_ybbnyy_byyyyy 352 372 C01-ascorbic acid _nnnYny_nnnnYn_nnnn?n_nnnnny_nnnnnn_nn?nnn_nnnnnn_nnnnnn_nnnnyn_nnnn?? 181024 C02-anthrone _yyYyyy_YYynYn_nnyn?n_yynyyn_nnnnnn_yynyyn_nynyyy_ynnyxy_ynyyyy_yyyy?? 3 968 C03-asparagine-DL _yyyyyY_nnnyny_yNyn?n_ynynny_nnyynn_yynnyn_ynnyny_nnnynn_nnynyn_nnyy?? 51 508 C04-benzoate Na _yynYyY_nnYyyY_Ynnn?n_yyyyny_nyynnn_nnnnnn_nnnnnn_nnnnnn_nnynyy_nnyy?? 12 832 C05 citrate Na _nyyyny_nnyyny_nnnn?n_yyyyny_nnynnn_ynnyyn_ynnyny_nnnnny_ynynyy_yyyy?? 481368 C06-cysteine-L _yNNNyy_Ynynyn_ynyn?n_ynnnny_nnnynn_yynyyn_nynyny_ynyynn_nnynyn_nnnn?? 28 800 C07-dulcitol _yyyyyy_ynyNyn_Nyyy?y_ynyyny_nnyynn_yyyyyy_yynyyy_yynyyy_ynyyyy_yyyy?? 69 896 C08-erythritol-meso _yNyyny_YYNnyn_yyyy?y_ynnyyy_nynynn_ynnyyy_nynnyy_nynyyn_yyyyyy_ynnn?? 7 69 C09-ethanolamine _yyyyyy_ynyNyy_yYyy?y_ynyyyy_?yyynn_yyyyyn_yynyyy_yynyyy_yyyyyy_yyyy?? 62 764 C10-gluconate-D Na _yyyyyy_ynyyy?_Nyyy?n_yyyyyy_nyyynn_ynyyyy_yynyyy_yynyyy_yyyyyy_yyyy?? 78 880 C11-hydroxyquinoline-8 _nnnnnn_nnnnnn_nnnn?n_nnnnnn_nnnnnn_nnnnnn_nnnnnn_nn?nnn_nn?nnn_nnnn?? 0 0 C12-hippurate Na _yyyyyy_yNyYyn_yyyy?y_yyyyyy_nyyynn_yyyyyy_yynyyy_yyyyyy_yyyyyy_yyyy?? 441024 C13-inositol _yyyyyy_ynynyY_Nyyy?y_ynyyyy_nnyynn_yyyyyy_yynyyy_ynnyyy_ynyyyy_yyyn?? 26 880 C14-lactate-DL Na _yyyyny_yNyyyn_Nyny?y_yynyyy_nyyyyn_yynyyy_nynyyy_yynyyn_ynyyyy_yynn??? 5?420 C15 lactose _yyyyyy_ynyyyy_nyyy?y_yyyyyy_nnyynn_yyyyyy_yyn?yy_yynyyy_yyyyyy_yyyy?? 80 924 C16-malate-DL _yyy???_ynyynn_ynyn?n_ynynny_nnynnn_yynyyy_yynyny_yyyyyy_ynynyn_yyyy?? 41 436 C17-malonate Na _yyyyyy_ynynyn_nyyy?n_yyyyny_nnyynn_ynyyyy_nynnyy_yynyyy_ynyyyy_yyyy?? 75 792 C18 maltose _yyyyyy_ynyyny_yyyy?y_yyyyyy_nynynn_yyyyyy_yynyyy_yynyyy_ynyyyy_yyyy?? 121336 C19-mannitol _Yyyyyy_YnyyyN_yyyy?n_ynyyyy_nnyynn_yyyyyy_yynyyy_yynyyy_ynyyyy_yyyy?? 411456 C20-melezitose-D _Yyyyny_Ynynyn_Nyyn?n_yynyny_yynynn_ynnyyn_nynyy?_yynyyn_yyyyyy_yynn?? 6 548 C21-barbital Na _yyyyyy_ynynyY_Nyyy?y_yyyyny_nnyynn_yyyyyy_yynyyy_yynyyy_ynyyyy_yyyy?? 711336 C22-thymol _nnnnnn_nnnnnn_nnnn?n_nnnnnn_nnnnnn_nnnnnn_nnnnnn_nnnnnn_nnnnnn_nnnn?? 0 0 C23-propionate _NyNyyy_nnYyyn_NYyn?n_ynynny_nnynnn_yynynn_nnnnnn_nnnnyn_nnnyyn_ynyy?? 22 0 C24-propanol-o _yyyyYy_yNyyyy_yyyy?n_yyyyny_nyyynn_yynyyy_yynyyy_yynyyy_ynyyyy_yyyy??? 28?776 C25-riboflavin _nnnnnn_nnnnyn_nnnn?n_ynnnny_nnnnnn_ynnnnn_nnnnnn_ynnn??_ynnyyy_yyyy?? ??72b C26-salicin _yyyyyy_YnYnYY_Yyyy?n_ynyyny_ynyynn_yynyyy_yynyyy_yynyyy_ynyyyy_ynyy?? 471568 C27-sorbitol _yyyyyy_ynyyyY_yyyy?n_yyyyyy_ynyynn_ynyyyy_yyn?yy_yynyyy_ynyyyy_yyyy?? 261232 C28-sorbose _yyyNyN_ynyyyn_yyyy?y_?ynyny_nynnnn_yyyyyy_nnnyyy_yynyyy_ynnyyy_yyyy?? 5 952 C29-succinate Na _yyNyyy_ynyyyN_yy?y?n_?nyyny_nnyynn_yynyyy_yynyyy_yy?yyy_ynyyyy_yyyy?? 40 728 C30-tartrate-L Na _y?yyyy_ynyyYn_nyyy?y_yyynyy_nnynnn_yynyyy_nnnyyn_yynyyy_ynyyyy_yyyy?? 39 896 M01 AlCl3.6H2O 300_ynynyy_ynsbsn_yyyyyy_yyyyyy_yyyy??_sb?ysy_yyynyy_snnyyy_ssyyyy_y?yyyy 260 406 M02 BaCl 2000_yyyyyy_nnyyyn_yynyyn_sbyyby_ybyy??_sy?yyy_yybnyn_ybnyyy_nbbn?y_bsyyyy 3601360 M03 CoCl2.H2O 10_ysyyyy_ynybyy_yynyyb_syyyyy_nbyynn_sy?yyy_yyynyy_ybnyyy_yybnyy_yyyyyy 130 500 M04 CrK(SO4)2.12H2O 500_ysbyyy_ynybyy_ynynyn_ynyyny_ynyn??_yb?yyy_yyyyny_nnnbnb_nnynyy_byyyy? 561000 M05 K2Cr2O7 10_yssyyy_ynyyyy_yyyyyb_yyyyyy_bnyy??_sy?yyy_yyyyyn_snnyyy_?ybnyy_yyyyss 294 860 M06 CuCl2.2H2O 100_nnnnnn_nnnnnn_nnnnnn_nnnnnn_nnnn??_nn?nnn_nnnnnn_nnnnnn_nnnnnn_nnnnnn 1 0 M07 CuCl2.2H2O 20_nnnnnn_nnnnnn_nnnnnn_nnnnnn_nnnn??_nn?nnn_nnnnnn_nnnnnn_nnnnnn_nnnnnn ?0?3? M08 CuSO4.5H2O 20_nnnnnn_nnnnnn_bnnnnn_bnnnnn_nnnn??_nn?nnn_nnnnnn_nnnnnn_nnnnnn_nnnnnn 114 27 M09 FeC6H5O7:XH2O 300_ysysys_ynyyyn_ynynyn_snyyny_bnyy??_sy?yyn_yyyyyy_nnnyny_nyynyy_syyyyy 2051656 M10 La(NO)3xH2O 150_ysyyyy_yynysy_yynyyn_ynyyny_ybyynn_sy?ssy_ysyyyy_yynnsy_ysynyy_yyyyyn 384 812 M11 LiCl.H2O 2000_yssbyy_bn?nsn_yynnyn_ynyyny_ynyy??_sy?ynn_yynyny_nnnyyy_yyynyn_nyyyyy 2181720 M12 MnSO4 2000_nsnnyy_nnnnbn_nnnynn_sbynnn_nnyn??_sn?nnn_nnnnnn_nnnnbn_nnnnsb_nnyyyn 108 218 M13 MnSO4 5000_nynnnn_nnnnnn_nnnnnn_ynbnnn_nnbnnn_yn?nnn_nnnnnn_nnnnnn_nnnnnn_nnbnnn ? ? M14 NiCl2.6H2O 10_nnbnyn_nnnynn_nnnnnn_nnybnn_bnyb??_yy?nyn_ynnnnn_nnnnnn_nnbnnn_nbyybn 212 260 M15 PbAc 500_ysyyys_ynyyyy_yyyyyn_yyyyyy_yyyy??_sy?sss_yyyyyy_ynnyyy_yyynyb_byyyyy 5681368 M16 SeO2 300_yyybny_nnnnnn_snynsn_yynyny_nnny??_yy?byy_bybnyy_yynyyn_yyynbb_bynnby 16 292 M17 TlCl2 20_nynnnn_nnnnny_nnnnnn_nnnnnn_ynnn??_nn?nnn_bnbnnb_nnnnyn_nnbbyb_nnnny? 11 28 M18 VO3NH4 2000_nnnnyn_nnnnyn_nnnnyn_nnynnn_nnyn??_nn?nnn_ynynnn_nnnnnn_nnnnbn_nnyynn 80 520 M19 WO4Na2 2000_sysnys_snsysn_sssnyn_snynny_ynyy??_yy?yyy_yyyyyy_ybnyyy_ynbnyb_byyyyy 2101048 M20 ZnSO4 20_ysyyyy_yyyyyy_ynbnyn_snyyby_y?yy??_sy?yyn_yyyyny_bnnyyy_ybyyyy_yyyyyy 161 596 M21 MgSO4 2000_ysyyyy_ynyyyn_sybnyn_snyyby_ybyy??_sy?yyy_ynyy?y_ynny?y_yyb?yy_y?yyyy 340 556 M24 KBr 1000_ysyyys_ynyyyy_yygyyn_sbyyby_byyy??_sy?ssn_yyyyyy_yynyyy_yyynyy_yyyyny 2021656 M25 NaF 500_ysysys_ynyysn_snbnsn_sbyyny_ybyy??_yy?yyy_yyyyyy_ynnyyy_ynyyyy_byyyyy 262 880 M26 HgCl2 1_yyyyyy_ynyyyy_yybyyn_sbyyyy_byyy??_sy?yyy_yyyyyy_yynyyy_?ybyyy_yyyyyy 148 178 M27 K2SO4 5000_ysyyyy_ynyysn_ynynyn_snsyny_ynyy??_sy?yyy_yyyyny_nnnyny_ybbnyy_nyy?y? 240 760 M29 TiO2 10000_yyyyyy_ynyyyn_yyyyyb_syyyyy_bnyy??_sn?yyy_yyyyyy_ynnyyy_yyynyy_yyyyyy 87 576 N01-glutamate-L Na _yyyyyy_Ynyyyn_Nyyy?n_ynyyny_nnyy??_yynyyn_yyyyyy_yyyyyy_ynynyy_yyyy?? 39 680 N02-lysine-L _yyyNyy_Ynyyny_yNyn?y_ynynyy_nnyynn_ynnnyn_yynyny_yyyynn_ynynyy_yyyy?? 85 520 N03-proline-DL _yyyyyy_ynyyyN_yyyn?n_y?yyny_yyyynn_yyyyyy_yynyyy_yyyyyy_yyyyyy_yyyy?? 104 776 N04-serine-L _yyyyyy_ynyyyN_yyyy?y_yyyyny_nynynn_nynyyy_yyyyyy_yynyyy_ynyyyy_yyyy?? 571052 N05 tyrosine-D _yyyyyy_ynyyyn_yyyy?y_yyyy?y_nyyynn_yyyyyy_nynnyn_yynyyy_yyyyyy_yyyy??? 15? 0 R01 KI 200_ynssys_ynsbyy_yyyysn_snnybn_nyyy??_sb?yyy_yyyyyy_ybnnnn_yybnby_yyyyyy 2941040 R02 NO3Na 2000_yssyss_ynyyyn_ynyysn_snyyny_bnys??_sy?yyy_yyyyyy_ybnyyy_y?ynyn_yyyyyy 103 448 R03 NaCl 15000_yybnyy_nnnbnn_ynbnbn_ynybnn_bnyn??_sb?nyn_yyyyny_nnnynn_nnbnyn_nnyyyy 166 876 R04 SDS 100_ysyyyy_ynyyyb_yyyyyy_yyyyyy_bbyy??_sb?sss_yyyyyy_ybnyss_yybnyy_yyyyyy 132 780 R05 bromothymol blue 750_ssysny_ynynyn_sbyyyn_snnnny_nnnn??_sn?yyy_nsnyyy_yynyyn_nyynyn_nnnnnyB 1B472 R06 methylene blue 1000_nnnnnn_nnnnnn_nnnnnn_nnnnnn_nnnn??_nn?nnn_nnnnnn_nnnnnn_nnnnnn_nnnnnn R07 congo red 3000_syybyy_nybys?_ybnnyn_snbynb_bbyy??_sn?syy_yyyyyy_ybnyyy_ybynyy_yyyyyyB 43B528 R08 crystal violet 20_nnnnnn_nnnnnn_nnnnbn_bnnnnn_nnnn??_nn?nyn_nnnyny_nnnnnn_nnynnn_nnnnnn 4 5 R09 malachite green 20_ysyynn_ynynbn_ynnnsn_snnynn_nnnn??_sn?yyb_nynyyy_nnnyby_ysynyn_n?nnyy 9 1 R10 nalidixic acid 50_ysyyyy_ynbbyn_yybysn_sbyyny_byyy??_sn?ssn_nynyyy_synyyy_yyynnb_byyyyy 426 608 R11 nalidixic acid 200_ysybyn_ynnysn_ynnbsn_ynynnn_yyyy??_sn?ssn_nynnyn_bynbyy_yynnny_yyyyyb 520 376 R12 berberine HCl 275_ysnynn_nnnnnn_ynynnn_snnnnn_nnnn??_sn?yyn_nynynn_nnnnnn_nnynyb_nnnnnn ?1 ?4 R13 glucose 300000_nnnnnn_nnnnnn_nnnnnn_nnnnnn_nnnn??_nn?nnn_nnnnnn_nnnnnn_nnnnnn_nnnnnn 0 0 R15 pH 9.0_ysyyyy_ynybyn_yynyyn_sbyyby_byyy??_sy?ssy_yyyyyy_ynnbyy_yyyyyy_yyyyyy 420 944 R16 pH 5.0_nnnnyy_ynnnyn_nyyyyn_sbbnny_nbyy??_yn?yy?_ynyyyy_nnnnnn_nnnnyn_nnynnn 781586 T01 growth on Bernaerts l_nsynyn_ynyysn_yyyysy_syyyyy_yyyy??_sy?ssb_ysyyyy_synsys_ynysyy_ysyysn 842376 T02 growth on bromoth b20_ssysns_snsnsn_ssysyn_synsby_nyny??_sn?sss_ysynyy_ynnyyy_nnny?y_ysnnsy 61 48 T03 growth at 4oC _n4n754_nnn49n_nn8nnn_9n6nnn_nn7n??_33?nnn_nnn3n3_nnnn9n_nnnn3n_nn86nn 16 724 T04 growth at 28oC on YMA_112231_4n321n_232n1n_152351_3622??_1n?312_111111_2nn313_3n1n13_532113 891000 T05 growth at 37oC on YMA_??????_??????_??????_??????_??????_11?32n_1n1n2n_nnn233_nn1n1n_n68n1n 292 856 T06 growth at 37oC on LB _3nnn3n_nnn1nn_3nnn1n_1nnnn1_1n4n??_n1?nnn_121nnn_nnn4nn_nn1n1n_nnnnnn 54 206 T07 TYtyrosine600CuSO4:40_nnnnnn_nnnnnn_nnnnnn_nnnnnn_nnnn??_nn?nnn_nnnnnn_nnnnnn_nnnnnn_nnnnnn 0 0 T08 Mg-free agar DM-Mg(Mn_nyyyny_yyyyyy_nnyn?y_ynyyyy_nnyn??_yn?yyn_y?y?ny_yy?yny_ynynyy_?yyy?? 27 800 T09 MnSO4 2000 at pH=5 _ysnnyy_ynnnyn_ybnynn_sbyyb?_nby???_yb?nyy_yyyyyy_ynnnyn_nnbnyb_ynyysy 164 660 T10 Onobrychis nodulation_nnnnnn_nnnnnn_nnnnnn_nnnnnn_nnnn??_nn?nnn_nnnnnn_nnnnnn_nnnnnn_nnnnnn T11 2 days at 37C _??????_??????_??????_??????_??????_??????_??????_??????_??????_?????? 210 544 T12 COLOR ON TO4ctd.nonrd_nnnnnn_nnnnnn_nnnnyn_nnnnny_nnnn??_nn?nnn_nnnnnn_nnnnnn_nnnnnn_nnnnnn 39 100 T13 CuO2 rings on T1 _ynnnnn_nnnnnn_nnnnnn_nnnnnn_nnnn??_nn?nnn_nnnnnn_ynnnnn_ynnnnn_nnnnnn NM0 YMA control _??????_?n?n??_??????_??????_??????_??????_??????_??????_??????_?????? 2483428 NM1 MILSOL*0.05 + YMA _??????_?n?n??_??????_???y?n_n??n??_?n??y?_n?n???_?y?n?y_?ny???_y????? 1803690 NM2 SELSOL*0.05 + YMA _??????_?n?n??_??????_???y?n_n??n??_?n??y?_n?n???_?y?y?y_?ny???_n????? 77 204 NM3 ethanolamine (=C09) _??????_?n?n??_??????_???n?n_n??n??_?n??n?_n?n???_?n?n?n_?ny???_n????? 164 0 NM4 tyrosine (=NO5) _??????_?n?y??_??????_???n?y_n??n??_?n??n?_n?n???_?n?n?n_?ny???_n????? 3081120 NM5 MILSOL*0.05 + C09 _??????_?n?n??_??????_???n?n_n??n??_?n??n?_n?n???_?n?n?n_?ny???_n????? 2321176 NM6 SELSOL*0.05 + C09 _??????_?n?n??_??????_???n?n_n??n??_?n??n?_n?n???_?n?n?n_?nn???_n????? 0 2 NM7 glucose 100000_??????_?n?n??_??????_???n?n_n??n??_?n??n?_y?n???_?n?y?n_?nn???_n????? ? 680 z01 bromothymol blue 20_s?ys?y_s?sys?_ss?s??_syssyy_?yss??_ssssss_ns?ysy_s??yns_ssby?s_yn???? 88 626 z02 chlaora+bromotbl+Co _??ny?n_s?nns?_sy?s??_synnbb_nynn??_snnssn_snnnsy_s??y?s_snbb?s_yynn??P 10 652 z03 pen+nal+bromot+bacitr_n?nn?n_s?nns?_sn?n??_snsnnn_nnnn??_snnssn_nnnnsn_n??n?n_ynnn?y_ynnn?? 5 45 z04 pen+bactitr _y?ny?b_y?yns?_by????_s?byyy_nynn??_syssss_nsnysy_y??y?n_yb?y?y_ynnn?? 31 208 z05 malg+bromot+Se+Co+ery_n?nn?n_n?nnn?_nn?n??_ynnbnn_nnnn??_nnnnsn_nnnnny_n??n?n_nnnn?n_nnnn?? 0 0 z06 malg+bromot+Se+Co+bac_n?nn?n_s?nnn?_nn?n??_bnnnnn_nnnn??_nnnnsn_nsnnny_n??n?n_bnnn?n_nnnn?? 1 3 z07 erythritol _n?ns?y_n?nbs?_nn?b??_bbbbbb_bbnb??_bbbssy_nynbby_y??y?n_nnys?y_yyyy?? 18 482 z08 lactate (pH=8.5) _n?ny?n_y?yyn?_nn?n??_ynnnny_nnyn??_??????_??????_??????_??????_?????? 192 708 z09 melezitose _n?ny?n_y?bbs?_ny?y??_sbbbbb_bbbb??_sbbsys_bbbbbb_s??s?s_bbbb?s_bbnb?? 100 434 z10 sorbose _n?nn?n_n?nby?_nn?b??_bnnbnb_nnnn??_??????_??????_??????_??????_?????? 12 6 z11 lactate+chlora+bro+Co_y?nb?n_y?nbb?_yy?y??_bbnnnn_bnnn??_nnnnsn_nsnnyy_s??b?n_snns?b_bbnn?? 3 430 z12 YMA _s?ys?s_s?sbs?_ss????_sysssy_?ysy??_ssysss_bybbyb_s??s?s_yyby?y_y?ss?? 481380 --------------------------------------------------------------------------------------------------------Note NM-NM7 and z01-z12 were not included in the numerical analysis and will be discussed in section 5. The left-to-right arrangement of strains in the data matrix is identical with the top-to-bottom listing of T-4.1-A (altogether 60 strains, thereof 54 used). For more convienient handling, a blank("_") has been left after each six strains. "CHE" and "GRA" refer to the number of colonies with control pour plates with Chengdu and Grassland soils.
--------------------------------------------------------------------------------------------------------
4.2.1. Microbial growth: Pour plate counts of plates inoculated with a loopful of frozen 2ml inoculation bottle (section 4.1.4.) backups gave 12(strain no. 19),5(strain no. 30),5(strain no. 9) and 2(strain no. 27) colonies respectively. Allowing for losses while freezing and pouring the agar, the average number of bacteria blotted on the agar plates was probably mostly between 10-100. However, it is conceded that the ratio of positive tests varied between 0.07 and 0.85 for different strains. Even if all strains below a ratio of 0.20 (8 and 41) as well as those with above a ratio of 0.80 (49 and 18) were excluded from the analysis, the remaining differences in the ratio of positives (0.23-0.79) was very wide.
4.2.2. Computation times: with the given data, the program PROG_CLU.C needed 5 minutes if run on a 586-processor PC and 5 hours if run on a 386-processor PC. The choice of the similarity coefficient does not affect running time markedly.
Diagram D-4.2-A: cluster analysis on OTUs, method:(1.Simple matching coefficient), 8 minimum positives/negatives required,maximum vigor distance allowed: 1.000000
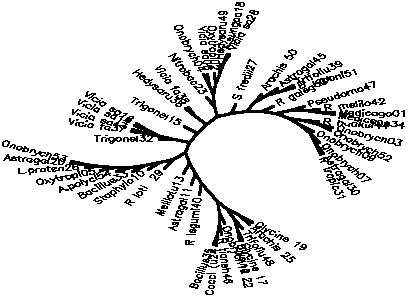
Treefile: ((R legumi40,(Astragal11,(Melilotu13,((R loti 29,(Staphylo10,(Bacillus33,(A.polycl54,(Oxytropi05,(L.praten26,(Astragal20,Onobrych53))))))),((Trigonel32,((Vicia fa37,Vicia sa43),(Vicia sa14,Vicia sa16))),(Trigonel15,((Hedysaru36,Vicia fa38),((Nitrobac23,((Onobrych04,Vicia sa06),(Oxytropi02,(Hedysaru49,(A.sungpa18,Vicia sa28))))),(S fredii27,((Arachis 50,(Astragal45,(Trifoliu39,B japoni51))),(R galega21,((Pseudomo47,(R melilo42,(Medicago01,Medicago34))),((R huakui44,(Onobrych03,Onobrych52)),(Onobrych09,(Onobrych07,(Astragal30,R tropic31)))))))))))))))),(((Glycine 19,Arachis 25),(Trifoliu48,(Glycine 17,Glycine 22))),(Onobrych12,(R tiansh46,(Cocci (u24,Bacillus35)))));
Diagram D-4.2-B: cluster analysis on OTUs, method:(1.Simple matching coefficient), 8 minimum positives/negatives required,maximum vigor distance allowed: 1.000000
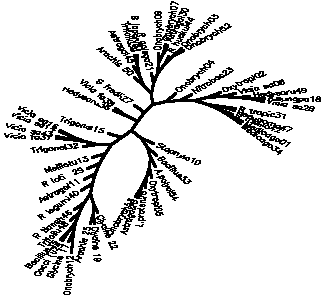
Treefile: (Onobrych12,(Glycine 17,((Cocci (u24,Bacillus35),(Trifoliu48,(R tiansh46,((R legumi40,(Astragal11,(R loti 29,(Melilotu13,((Trigonel32,((Vicia fa37,Vicia sa43),(Vicia sa14,Vicia sa16))),(Trigonel15,(((Hedysaru36,Vicia fa38),(S fredii27,(((Arachis 50,(Astragal45,(Trifoliu39,B japoni51))),(R galega21,((Onobrych09,(Onobrych07,Astragal30)),(R huakui44,(Onobrych03,Onobrych52))))),(Onobrych04,(Nitrobac23,((Oxytropi02,(Vicia sa06,(Hedysaru49,(A.sungpa18,Vicia sa28)))),((R tropic31,Pseudomo47),(R melilo42,(Medicago01,Medicago34))))))))),(Staphylo10,(Bacillus33,(A.polycl54,(Oxytropi05,(L.praten26,(Astragal20,Onobrych53))))))))))))),(Glycine 22,(Glycine 19,Arachis 25))))))));
4.2.3. Using similarity coefficients which to not care for vigor differences: The influence of the similarity coefficient chosen is big, especially on the lower branches of the tree. For instance, the simple matching coefficient (#Sneath 1973) seems to give some good results with clusters (44-52-3-7-9), (37-43-14-16), (42-1-34) and (19-25; 17-22) in D-4.2-A, but non-rhizobial control strains are mixed into the whole tree (e.g. 23;47) and higher phylogenetic relations are blurred. When applying the (#Sneath 1957) positive matching coefficient (D-4.2-B) the tree becomes more chained, but the overall picture doesn't change very markedly.
Diagram D-4.2-C : cluster analysis on OTUs, method:(3.Matching w/o vigor (Sneath 1968)), 8 minimum positives/negatives required,maximum vigor distance allowed: 1.000000

Treefile: ((Melilotu13,Cocci (u24),(Astragal11,(((Bacillus33,(Bacillus35,Hedysaru49)),(R loti 29,(Staphylo10,(Oxytropi05,(A.polycl54,(L.praten26,(Astragal20,Onobrych53))))))),((Glycine 19,Arachis 25),(((Vicia sa43,Trifoliu48),((Vicia sa16,(Vicia sa14,Nitrobac23)),((((Trifoliu39,(B japoni51,(Glycine 22,Vicia sa28))),((R legumi40,(Vicia fa37,(R tropic31,Trigonel32))),(Onobrych52,((R huakui44,(Onobrych09,(Astragal30,(Onobrych07,A.sungpa18)))),(Astragal45,(R melilo42,(Onobrych03,Glycine 17))))))),(S fredii27,(Medicago34,(Medicago01,R tiansh46)))),((Oxytropi02,(Onobrych04,Vicia sa06)),(R galega21,(Arachis 50,(Onobrych12,Pseudomo47))))))),(Trigonel15,(Hedysaru36,Vicia fa38)))))));
Diagram D-4.2-D: Wagner-Farris tree based on (b*c)/(n*n), maximum vigor distance allowed: 1.000000
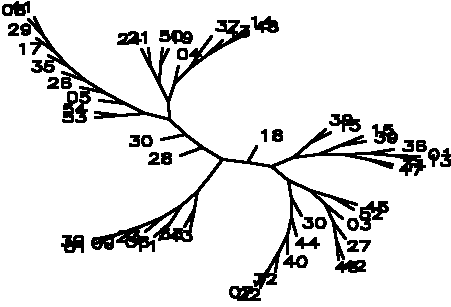
Treefile: ((( 43, 33),(( 11, 06),( 23,( 09,( 51, 39))))),(( 28,( 30,((( 53, 54),( 05,( 26,( 35,( 17,( 29,( 08, 41))))))),((( 24, 21),( 50, 19)),( 04,(( 37),( 43,( 14, 48)))))))),( 18,((( 39, 15),(( 15, 39),(( 36,( 01, 13)),( 34, 47)))),((( 45, 52),( 03,( 27,( 42, 46)))),( 30,( 44,( 40,( 32,( 22, 07))))))))));
4.2.4. Using the #Sneath (1968) matching-without-vigor coefficient: Control strains are now removed out of the major rhizobia cluster (D-4.2-C); however the tree is still suffering from very strong chaining (which is especially disastrous for the bradyrhizobia 19;25;23;22;51). A Farris-Wagner tree generated by selecting for maximal pattern distance also shows (two) main rhizobia cluster, and although not suffering from chaining, also scrambles vetch rhizobia into the bradyrhizobia (D-4.2-D).
Diagram D-4.2-E:cluster analysis on OTUs, method:(5.Chisquare), 8 minimum positives/negatives required,maximum vigor distance allowed: 1.000000
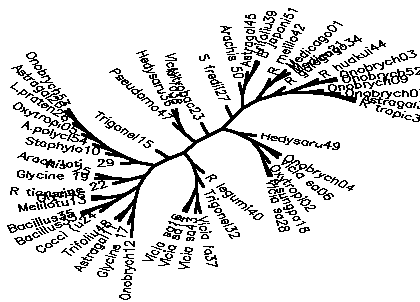
Treefile: (Onobrych12,(Glycine 17,((Astragal11,Trifoliu48),(((Cocci (u24,(Bacillus33,Bacillus35)),(Melilotu13,R tiansh46)),((Glycine 22,(Glycine 19,Arachis 25)),((R loti 29,(Staphylo10,(A.polycl54,(Oxytropi05,(L.praten26,(Astragal20,Onobrych53)))))),(Trigonel15,(((Pseudomo47,(Hedysaru36,Vicia fa38)),(Nitrobac23,((S fredii27,((Arachis 50,(Astragal45,(Trifoliu39,B japoni51))),((R melilo42,(Medicago01,Medicago34)),(R galega21,((R huakui44,(Onobrych03,Onobrych52)),(Onobrych09,(Onobrych07,(Astragal30,R tropic31)))))))),(Hedysaru49,((Onobrych04,Vicia sa06),(Oxytropi02,(A.sungpa18,Vicia sa28))))))),(R legumi40,(Trigonel32,((Vicia fa37,Vicia sa43),(Vicia sa14,Vicia sa16))))))))))));
Diagram D-4.2-F: cluster analysis on OTUs, method:(6.Modified chisquare), 8 minimum positives/negatives required,maximum vigor distance allowed: 1.000000
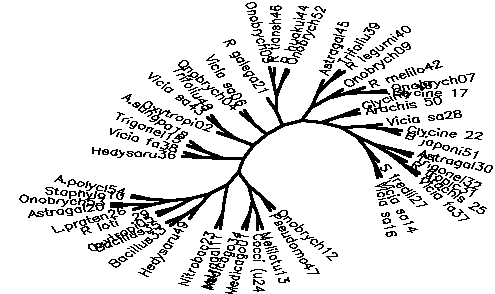
Treefile: ((Astragal11,Nitrobac23),(((Hedysaru49,(Bacillus33,Bacillus35)),((Oxytropi05,R loti 29),((L.praten26,(Astragal20,Onobrych53)),(Staphylo10,A.polycl54)))),((((Hedysaru36,Vicia fa38),(Trigonel15,A.sungpa18)),((Oxytropi02,(Vicia sa43,Trifoliu48)),((Onobrych04,Vicia sa06),((R galega21,((Onobrych03,R tiansh46),(R huakui44,Onobrych52))),(((Astragal45,(Trifoliu39,R legumi40)),(Onobrych09,(R melilo42,(Onobrych07,Glycine 17)))),((Glycine 19,Arachis 50),((Vicia sa28,(Glycine 22,B japoni51)),(((Astragal30,Trigonel32),(R tropic31,(Arachis 25,Vicia fa37))),(S fredii27,(Vicia sa14,Vicia sa16)))))))))),((Onobrych12,Pseudomo47),((Melilotu13,Cocci (u24),(Medicago01,Medicago34))))));
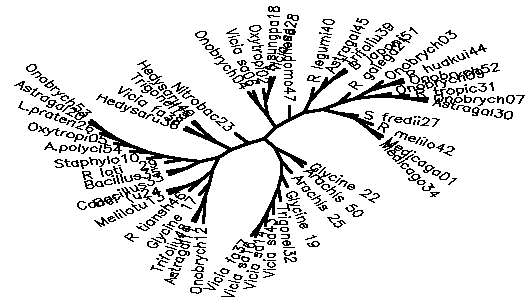
Diagram D-4.2-G: cluster analysis on OTUs, method:(7.Mixture of (5-6)), 15 minimum positives/negatives required,maximum vigor distance allowed: 1.000000
Treefile: ((( 48, 15), 17),( 11,( 23,(( 28,( 02,( 04, 06))),((( 21),( 47),(( 27, 46),( 13,( 01, 34)))),((( 22,( 25,( 19, 50))),(((( 40,( 45,( 39, 51)))),( 32,( 43,( 14,( 16, 37))))),((( 52, 44),( 03, 42)),( 31,( 07,( 09, 30))))))))))),(( 36, 38), 49),((( 35, 33), 24),( 29,( 10,( 54,( 05,( 26,( 20, 53))))))));
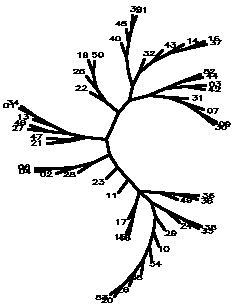
Diagram D-4.2-H: cluster analysis on OTUs, method:(7.Mixture of (5-6)), 15 minimum positives/negatives required,maximum vigor distance allowed: 0.300000, invalid tests not counted
Treefile: ((( 48, 15), 17),( 11,( 23,(( 28,( 02,( 04, 06))),((( 21),( 47),(( 27, 46),( 13,( 01, 34)))),((( 22,( 25,( 19, 50))),(((( 40,( 45,( 39, 51)))),( 32,( 43,( 14,( 16, 37))))),((( 52, 44),( 03, 42)),( 31,( 07,( 09, 30))))))))))),(( 36, 38), 49),((( 35, 33), 24),( 29,( 10,( 54,( 05,( 26,( 20, 53))))))));
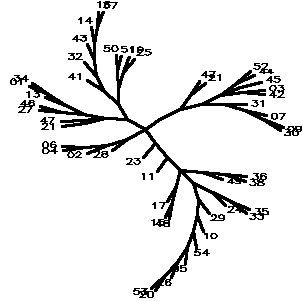
Diagram D-4.2-I: cluster analysis on OTUs, method:(7.Mixture of (5-6)), 15 minimum positives/negatives required,maximum vigor distance allowed: 0.300000, invalid tests not counted, OTU no. 39 omitted
Treefile: ((( 48, 15), 17),( 11,( 23,(( 28,( 02,( 04, 06))),((( 21),( 47),(( 27, 46),( 13,( 01, 34)))),(( 41,( 32,( 43,( 14,( 16, 37))))),(( 50, 51),( 19, 25)))),((( 47, 21),((( 52, 44),( 45),( 03, 42)),( 31,( 07,( 09, 30))))))))),(( 36, 38), 49),((( 35, 33), 24),( 29,( 10,( 54,( 05,( 26,( 20, 53))))))));
Diagram D-4.2-J: cluster analysis on OTUs, method:(7.Mixture of (5-6)), 5 minimum positives/negatives required,maximum vigor distance allowed: 1.000000, invalid tests not counted, data based on C/N utilization exclusively
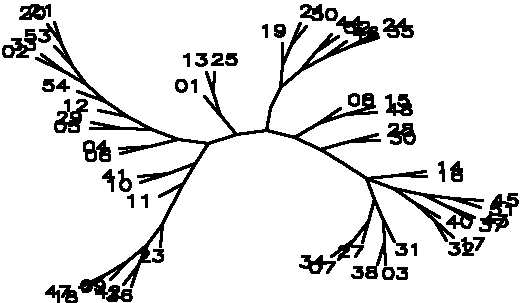
Treefile: ((23,(( 36, 42),( 09,( 18, 47)))),( 11,(( 10, 41),((( 06, 04),(( 05, 29),( 12,( 54,(( 02, 33),( 53,( 20, 21))))))),(( 01,( 13, 25)),(((( 19,( 21, 50)),(( 44, 52),( 46,( 24, 35))))),(( 08,( 15, 48)),(( 28, 30),((( 14, 16),((( 45, 51),( 43, 37)),( 40,( 17, 32))),(( 31,( 03, 38)),( 27,( 07, 34)))))))))))))))));
4.2.5. Using chi-square based coefficients: With the pure chi-square as coefficient, the tree is less chained now, the rhizobia cluster is also rather good, but bradyrhizobia still don't cluster together (D-4.2-E). The modified chi-square (D-4.2-F) looks more like D-4.2-C (scrambled vetch-bradyrhizobia cluster). A semimodified chi-square gives good species-level clusters (D-4.2-G). This can be improved by not counting those tests always negative and restricting the vigor difference level for clustering to DV(Vigor difference)<0.3 (D-4.2-H). If the data for strain 39 are omitted, an even more esthetic tree arises (D-4.2-I). D-4.2-J is a tree generated under the same conditions as D-4.2-G with only C/N-utilization data scored.
------------------------------------------------------------------------------------------------------- Table T-4.2-B: Maximal clusters generated by different coefficients -------------------------------------------------------------------------------------------------------- Coefficient Diagram Vetches Bradyrhizobia Sinorhizobia Xiaman-huakuii rhizobia Contr. Simple matching D-4.2-A 37-43-14-16 17-22 + 19-25 42-1-34 44-52-3-9-30-7-31 3 Positive match. D-4.2-B 37-43-14-16 19-25 1-34-42 44-52-7-9-3-30 4 Match w/o vigor D-4.2-C dispersed + 19-25 1-34-46-27 3-17-42-45-44-7-18-30-9 0 ibd.Wagner/Farr D-4.2-D 39-14-43 + dispersed 1-13--34 + 42-46-27-3-52-45 5 Chisquare coeff D-4.2-E 14-37-16-43 19-22-25 42-1-34 44-52-3-30-31-7-9 2 Modif Chisquare D-4.2-F 14-16 + 19-50 1-34 dispersed 1 Semimodif chisq D-4.2-G 16-37-14-43 50-22 27-42-1-34 7-30-9-31(?)-44-52-3 2 *w/o inv,vig<.3 D-4.2-H 16-37-14-43 19-50-25-22 13-1-34-27-46 9-30-7-31(?)-42-3-44-52 1 ** w/o 39 D-4.2-I 16-37-14-43-32-40 19-25-50-51+17-22 1-34-13-46-27 9-30-7-31(?)-44-52-45-42-3 1 C/N utiliz. D-4.2-J 19-21-50 + 14-16 7-34-27--3-31 44-52 --------------------------------------------------------------------------------------------------------Note: Contr. refers to the number of control strains "contaminating" that part of the tree containing all type strains. --------------------------------------------------------------------------------------------------------
4.2.6. Taxonomy of rhizobia: The different methods give several clusters of different quality (T-4.2-B), we believe a situation like one encountered in D-4.2-I to be most close to a natural classification and that is there is a vetch cluster (16-37-14-43--32-40) with a very sharply defined core (16-37-14-43), a somewhat profuse Bradyrhizobium cluster (19-22-25-50-51-17), a Sinorhizobium cluster (13-1-34-27-46) which sometimes mixes with a Xiaman-huakuii cluster (9-30-7-31-44-52-45). The close group (3-42) is either part of the Sinorhizobium or the Xiaman-huakuii cluster, but judging from the given data cannot be attributed with certainty to any of them. None of the rhizobial strains seems closely related to either R. galegae (29). It was decided that the strain of R.loti used (which should be related to R. huakuii or at least with rhizobia) was contaminated. Nothing certain can be said about strain (39). The strains (2;4;6;28--15;12;48;49;36;38;11;54;5;26;20;53) are termed the freezer bacteria cluster (no rhizobia). Note that the closely related freezer bacteria subcluster (5/6-20-26-53-54) shares the common characteristic of forming slightly pink colonies after two weeks and was isolated from nodules stored in paraffin at 4oC for several months.
-------------------------------------------------------------
Table-4.2-C: Differentiating characters between clusters
--------------------------------------------------------------
medium Xiaman-huakuii vs. vetch
5000ppm K2SO4 (7/7) (1/6)
citrate as C source (6/7) (0/6)
2000ppm MnSO4;pH5 (0/7) (5/6)
Sinorhizobium vs. Xiaman-huakuii
50ppm erythromycin (5/5) (2/7)
citrate as C source (0/5) (6/7)
tartrate as C source (1/5) (7/7)
rhizobia vs. freezer bacteria
growth at 4oC (1/22) (14/15)
-------------------------------------------------------------
4.2.7. General information yield of different biological tests for the differentiation of fast-growing rhizobia: Optimal information yield (positives 40-60%) was obtained by media A02,A03,CO6,N02,T08,T09. Slightly too permissive (60-70% positives) C02,M04; somewhat too permissive (70-80% positives) C02,M04,C16,C30,M09,M11,M20,M21,M27,R07;slightly too inhibitory (30-40% positives): C05,R03,R16; somewhat too inhibitory (20-30% positives): C03,M14,R12; although few studies gave data on the information content of the tests they employed this seems to show that there are many cases where autoclaving clearly does not influence the differentiating ability of a selective agent. When the results of similar tests were to checked with published descriptions of type strains, the number of directly comparable tests having the identical result as in the respective publication was 7 of 8 for S. tianshanensis (#Chen 1995), 5 of 5 for R. galegae (#Lindstroem 1989), 6 of 8 for S. fredii (#Scholla 1984), 8 of 10 for R. tropici (#Martinez-Romero 1991) and 13 of 20 for R. huakuii (#Chen 1991). However, it should be emphasized that in T10 no nodules were formed with any strain.
Diagram D-4.2-K: cluster analysis on tests, method:(6.modified chisquare), 5 minimum positives/negatives required,maximum vigor distance allowed: 1.000000
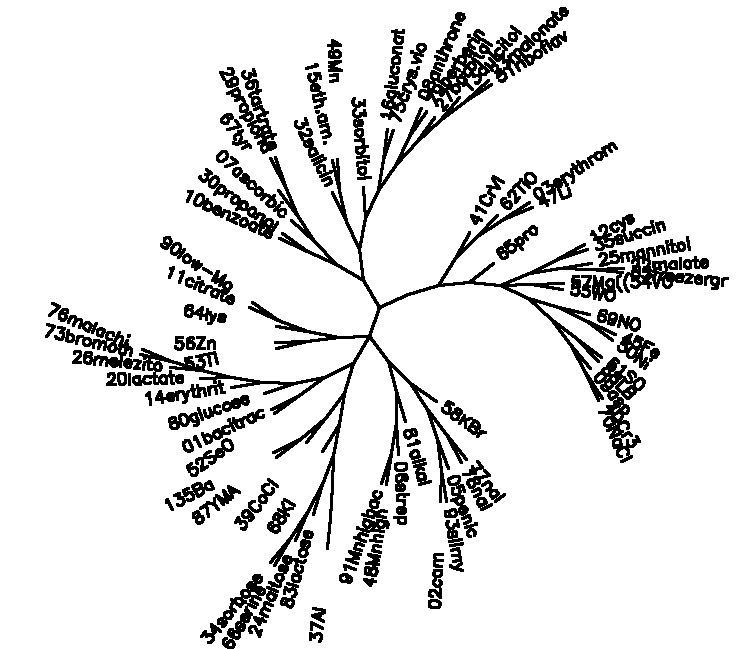
Treefile: ((37Al ),((83lactose ,(24maltose ,(66serine ,34sorbose ))),(68KI ,((39CoCl ,(87YMA ,135Ba )),(((52SeO ,01bacitrac),(80glucose ,(14erythrit,(20lactate ,(26melezito,(73bromoth,76malachi )))))),(((53Tl ,56Zn ),(64lys ,(11citrate ,90low-Mg ))),((((10benzoate,30propanol),(07ascorbic,(67tyr ,(29propiona,36tartrate)))),((32salicin,(15eth.am. ,49Mn )),(33sorbitol,((16gluconat,75crys.vio),((08anthrone,79berberin),(27barbital,(13dulcitol,(23malonate,31riboflav)))))))),(((41CrVI ,(62TiO ,(03erythrom,47Li ))),(65pro ,(((12cys ,35succin ),(25mannitol,(22malate ,85freezergr))),(57Mg((54VO ,55WO ),((69NO ,(45Fe ,50Ni )),((61SO ,88LB ),(09asp ,(40Cr3+ ,70NaCl ))))))))),((58KBr ,((77nal ,78nal ),(05penic ,(93slimy ,02cam )))),(81alkal ,(06strep ,(48Mnhigh ,91Mnhighac))))))))))));
4.2.8. Taxonomy of biological tests: The modified chi square seemed to give the most plausible results (D-4.2-K): among the early pair clusterings are: Cr3+ and NaCl resistance, FeAc and NiCl2 resistance, resistance to MnSO4 (2000) at pH=5 and pH=7, resistance to K2SO4 and growth on LB medium, resistance to bromothymol and malachite green, use of malonate and riboflavin, use of propionate and tartrate, use of citrate and growth of Mg-free medium, use of malate and growth at 4oC, resistance to nalidixic acid at 50 and 200ppm, resistance to berberine and use of anthrone.
4.2.9. Feasibility of plate design: Although each plate had to be opened thirty times when blotting the liquid-diluted rhizobia (sect. 4.1.4), this seldom resulted in contaminants. As the clustering results given above seem to be satisfactory, it also seems that different bacterial colonies blotted at distances of 7-10mm do not influence each other's growth extensively. At least within the 9 days cases of one colony overgrowing another to invisibility were rare (less than 20 in 5400 data).
4.3.1. General microbiological methods: The agar plate design allowed to do the investigation with a low amount of glassware. However, part of the strong differences in vigor of the data obtained have possibly been caused by unequal numbers of bacteria blotted onto the plates and it might be better to ascertain that an equal number of bacteria is applied each time. Furthermore, it would have been better to do duplicate tests, which could have generated clearer data. Notwithstanding, with the given data a foolproof method of analysis had to be developed.
4.3.2. Towards a more robust similarity coefficient: For optimizing the quality of similarity coefficients, we chose the UPGMA algorithm rather than Farris-Wagner trees, as with the UPGMA algorithm the plausibility of a coefficient can usually assessed after a few clustering steps. Some authors (#Novikova 1994) do not even mention which way the similarity was assessed. Even if we a assume the simple matching coefficient by default, the latter is difficult to use when different growth rates are encountered, for instance #Xu(1995) proved the uniqueness of extra-slow growing bradyrhizobia by numerical taxonomy using the simple matching coefficient, which implies that observations from different incubation times had to be compared, and he wisely asserted the uniqueness of the new species by a variety of other methods (G/C content, DNA-DNA hybridization, serology, 16 S rRNA sequencing etc.). In our study, it was evident that the simple or positive matching coefficient didn't work well due to huge differences in vigor.
-------------------------------------------------------------------------------
Table T-4.3-A: Different similarity coefficients allowing for different vigor
--------------------------------------------------------------------------------
Simple matching (a+d)/n
Positive matching a/(b+c+d)
#Sneath 1968 -(b*c)/(n*n)
Chisquare square((a*d)-(b*c)-0.5*n)*n/((a+b)*(d+b)*(a+c)*(d+c))
modified Chisquare (if, for instance, a less than d and b less than c)
(a-1)/(b*b)-(b-1)/(a*a)-2/(a*b)
semimodified Chisquare (if, for instance, a less than d and b less than c)
square((a*(a+d))-(b*(b+c))-0.5*(3a+3b+c+d))*(3a+3b+c+d)/
((2a+2b)*(a+d+2b)*(2a+b+c)*(a+b+c+d))
--------------------------------------------------------------------------------
Note: simplified for those parts relevant for relative similarity
n: Total number of biological tests for which data for both strains are available
Contingency table for both strains:
a: both strains +, b: strain 1 + & strain 2-, c: strain 1- & strain 2+, d: both strains -
S: similarity coefficient
--------------------------------------------------------------------------------
The matching-without-vigor coefficient proposed by #Sneath (1968) works very well for far taxonomic distinctions, in our own study it places 100% of the known control strains out of our putative rhizobial cluster. However, there is one fundamental difference between the positive or simple matching coefficient and concepts considering vigor: Whereas matching coefficient-based taxonomies are not influenced by the absolute number and overall ratio of positive and negative tests, vigor-considering taxonomies are. As in our data the ratio of positives differed in a wide range, many strains with very many positives (or negatives) were easier clustered than strains having 50/50 positives/negatives, as in the respective contingency table either b or c became small in that cases. This made the lower taxa become very blurred and in our study was disastrous for the vetch cluster.
In this situation, we felt that if in a contingency table the values for a and d are approximately equal (both strains share many positive and negative characters), the strains should be seen more related than strains either only sharing many positive or many negative tests. A weakness of Sneath's 1968 algorithm is that it discards all information on the proportion of a and d.
A common statistical method for analyzing contingency tables is the Chi square test, which we subsequently tried. To keep the value of similarity between 0 and 1, we defined similarity as chi/(chi+1), although this definition is not necessarily "meaningful" it allows to use the same computing algorithm and the thus-defined similarity function of chi satisfies strict monotony in the range of possible chi values. As anticipated, those pairs of strains in which both partners happen to share near 50% positives and 50% negatives were very strongly favored, as their a*d value UPGMA selects for is especially high. Though it gave us a beautiful vetch cluster, those clusters with rhizobia with differing vigor were (partly) dispersed and the higher taxa were not so clear as with the Sneath (1968) coefficient.
To make the test even more conservative, it was then considered to evaluate only those data in the contingency table which were minimal (in the contingency table this means that the upper of the a & d and c & b was replaced by the minimal value), which, as it was thought, should give the algorithm back some of the features of the Sneath (1968) coefficient, as it also strongly selects for a small b*c. However, though higher taxa became a bit more ordered, the scattering of lower taxa showed this was an overcorrection again. It was then decided to choose a medium modification of the chi square methods, that is the upper of the a & d and the c & b was each replaced by the average of both values.
The resulting algorithm thus requires a & d both to be high and slightly favors situations in which a and d are similar, which seems to give reasonable results on both near and far taxonomic levels for a study of organisms with widely differing vigors, it should however be modified for datasets allowing very wide variation in character positives, where the pure modified chi square is better than the semimodified chi square, such as the classification of biochemical tests (sect. 4.2.8.). As phenotypic characterization is at the moment a rather silent backwater in bacterial classification, it might be pointed out that the (semi-)modified chi square algorithm also might prove useful with more "advanced" data, for example genomic fingerprinting (gel bands) data for organisms with widely differing genome length or quality of isolated DNA.
4.3.3. Plasticity of trees generated: A current trend in taxonomy is to publish a most parsimonious tree generated by an algorithm on a dataset. Although, this is a very objective (a priori predetermined) way, it might not always fit best the diversity of the data encountered. The idea of minimal evolution might have a good theoretical justification when applied to random sequence changes, but it does not necessarily fit to microbiological growth data. Mayr (in #Felsenstein 1986) once remarked, that although it is good to get a parsimonious tree, "why should we be so obsessed to get the most parsimonious one?" when there are so many good trees. It might be objected that our hermeneutic approach of modifying the algorithm until something esthetic is found is subjective, but it is emphasized that our selection for good trees was mainly based on two principles: (1) the control strains should not be in the rhizobia cluster containing the proven type strains, or, if this is inavoidable, at least in the lower branches (higher taxa), (2) the bradyrhizobia (including three type strains instead of one for most other groups) should cluster closely together. The aim (2) was especially difficult to accomplish as in the design of this study (a) intentionally some tests designed for the only aim of separating fast- and slow-growers were omitted (the common tests for this include maltose,inositol,lactose,cellobiose,raffinose,ribose and sucrose,see DATASET.SEL; only the former three have been included in our study) and (b) after this goal had been predefined, the authors resisted the temptation to score growth speed as a valid characteristic (compare for example, #Novikova 1994, who gave growth speed the weight of five characters). No bias at all was taken towards the relations of any grassland strains, and we feel a bit reassured in our approach in that the not-at-all-anticipated distinction of freezer organisms (all clustering except one among the control strains) and non-freezer organisms (all clustering except one among the rhizobia type strains) is such a sharp one. It also might be objected that our study extensively uses resistance against salts and other agents and for this case we also made a tree (D-4.2-J) based on C/N utilization data alone. As more than half of the data was discarded, the tree looks a bit more disordered, but its general features (many of the original clusters, separation of rhizobia and non-rhizobia) remain preserved.
We basically believe all trees to give different aspects of the same taxonomic situation (a conclusion similar to #Mannetje 1967), but could not abstain to generate one for those who long to see an authoritative final result: the semimodified chi square tree can even more optimized by restricting the maximal vigor difference for clustering to smaller than 0.3 and not counting those tests which gave no positives for any of the strains. To show the plasticity of the tree more plainly, the authors arbitrarily did a little dendrosurgery and removed (39), (this "ulcer" had been isolated from a very small Chengdu white clover nodule) and it the spurious branch created by that strain collapsed and all other strains took their anticipated positions.
4.3.4. Putative grassland rhizobia cross-inoculation groups derived from the taxonomy and practical implications for grassland rhizobial techniques: The vetch rhizobia from Huanglongsi are doubtless close to the Chengdu vetch isolates. The inclusion of a Trigonella-derived strain (32) is surprising (as most authors, such as #Fred 1932 usually asume fenugreek to be nodulated by medic rhizobia), but as this strain was copied several times during maintenance a cross-contamination cannot be definitely ruled out, in brief: more strains should be checked before coming to rash conclusions about the status of Trigonella archiducis-nicolai rhizobia.
As pointed out before, young sainfoin (Onobrychis viciaefolia) was found to be poorly nodulated (even bigger nodules on older plants usually being of greenish color). Although very early workers usually assigned sainfoin to an independent inoculation group (#Mueller 1925, #Fred 1932)2, sporadically Onobrychis strains also have been clustered to S. meliloti (such as #Prevost 1987). In our study, the strain consistently clustering most closely to the S. meliloti type strain is indeed an Onobrychis strain (3), and perchance this also is the only grassland strain coming from a plot we had preinoculated (section 3): the strain mixture of the spot the strain came from was inoculated with a mixture of strains which among other Astragalus and Oxytropis strains indeed contained isolates from wild medic at Huanglongsi/Songpan (ca. 100km east of Ruoergai, similar climate).
On the evidence that the cluster (3-42) contains the type strain of S. meliloti and that the Onobrychis strain (3) is possibly medic-derived, it one could tentatively join them with the other Sinorhizobia to form a pure Sinorhizobium cluster. It should be noted , however, that the medic isolates seem to comer closer to S. tianshanense and S. fredii than to the anticipated S. meliloti type strain.
The other sainfoin rhizobia mix with the wild Astragalus rhizobia and the (Astragalus-sinicus-derived) Rhizobium huakuii. Astragalus rhizobia have been known to form a very diverse group (#Wilson and Chin 1947). It is a bit surprising that R. tropici also is in the lower branch of this group, which of course could also be due to a convergent evolution towards strong ion concentration resistance. In similar environments in Canada, #Prevost 1987 has shown that cultivated Onobrychis can be effectively nodulated by wild Astragalus and Oxytropis rhizobia which formed shared common clusters. However, our wild Astragalus-Onobrychis rhizobia differ from the Canadian isolates in that at least on agar plates incubated at 4oC for nine days no growth occurs. Despite this difference, the existence of a large-host-range temperate rhizobia cluster extending over the Galegeae (Astragalus, Oxytropis, Glycyrrhiza) and Hedysareae (Hedysarum, Onobrychis) has also been shown by #Novikova (1993,1994) and it might be speculated that a similar situation has been found in Xiaman.
If we accept these assumptions as a working hypothesis (which should be ascertained by a higher number of strains and a more polyphasic taxonomic approach), this suggests that there are few Sinorhizobia in natural Xiaman grassland soils and that inoculation with Sinorhizobia might lead to a change in the Onobrychis rhizobial symbiont (it however is absolutely unclear whether that change is beneficial or detrimental). On the other hand, other potential sources and competitors for sainfoin inoculation which should be assessed in an inoculation program can be isolated are R. huakuii-relatives from Astragalus spp., the field investigations (sect. 2) having shown that there is a wide range of nodule quality in different legumes.
4.3.5. Biology of rhizobia: The taxonomy of biological tests suggests that the uptake mechanisms for Fe2+ and Ni2+ (both of similar ion radius) might be similar, similar mechanisms for the use of short carbonic acids exist and that the "ability to use citrate as sole C source" is mainly an ability to withstand distortions in divalent ion equilibrium by a strong chelating agent.
Other associations such as the joining of Cr3+ and NaCl are caused by the inclusion of freezer contaminants in the study. It also should be noted that most associations are intra-batch, the first exemption being the clustering of polycyclic aromates berberine resistance and anthrone use.
Although it might be objected that these bold conclusions are based on too little and too unreplicated data, our argument is that data used for rhizobial taxonomy could as well be used to find out more about biochemically related features, which might stimulate new questions and new research in rhizobial biochemisty. Even commercially available programs (maybe not designed for investigations like this) can be most easily "cheated" to perform similar analyses - you just have to swap the input matrix.
It would be interesting to compare the data of different
independant taxonomic studies and to do similar investigations. In
the meanwhile, it is advisable to follow Sneath (1957A:193): "The
best method of showing one's results is to publish the full table
of all the results with every strain."It's a pity that hasn't been
done before, but electronic publication should be no problem in the
90s with so cheap data storage and networking power.
4.3.6. Addendum: On 14 Feb 1997, Prof. Sneath kindly wrote "we are not sure that the new similarities make sense intuitively. If one changes (a+d) to (a+d)/2 and (b+c) to (b+c)/2 then chisquare becomes (m-n)2/n where a+d=m and b+c=n. This will be zero when m and n are very different, and thus is not affected by transformation of the x/(x+1) type. So we wonder whether there is at present anything better than the usual pattern coefficients. However, as I do not know much about rhizobia, I cannot comment on whether the various coefficients make biological sense, it may be that there are other approaches that could help which it may be worth exploring". As a comment, I'd like to add that dealing with the above-mentioned data (a+d) was always larger than (b+c). However, as I admit I'm not very sure about the validity of these coefficients myself, please feel free to experiment with my and other coefficients your own datasets and tell me the results.